

At the International Supercomputing Conference in Leipzig, Germany, Intel Corp. unveiled additional details regarding its next-generation Xeon Phi co-processor code-named “Knights Landing.” As it appears, the KNL chip will not only offer breakthrough performance, but it will also provide breakthrough programmability thanks to the fact that it will feature modern cores with the Silvermont micro-architecture.
Intel Xeon Phi “Knights Landing” co-processors will be based on the Atom cores powered by the Silvermont micro-architecture enhanced with four-thread per core multi-threading technology as well as AVX512 instructions. Previously Intel used rather outdated Pentium-like (P54C-like) cores in its Xeon Phi co-processors. The new processing engines will help the company to increase single-thread performance of the new accelerators by up to three times compared to predecessors, which will allow to run more sophisticated applications and eventually solve more complex tasks. The new “Knights Landing” co-processors will feature up to 60 cores and will provide up to 3TFLOPS of SP/DP performance. The chips are to be made using 14nm process technology.

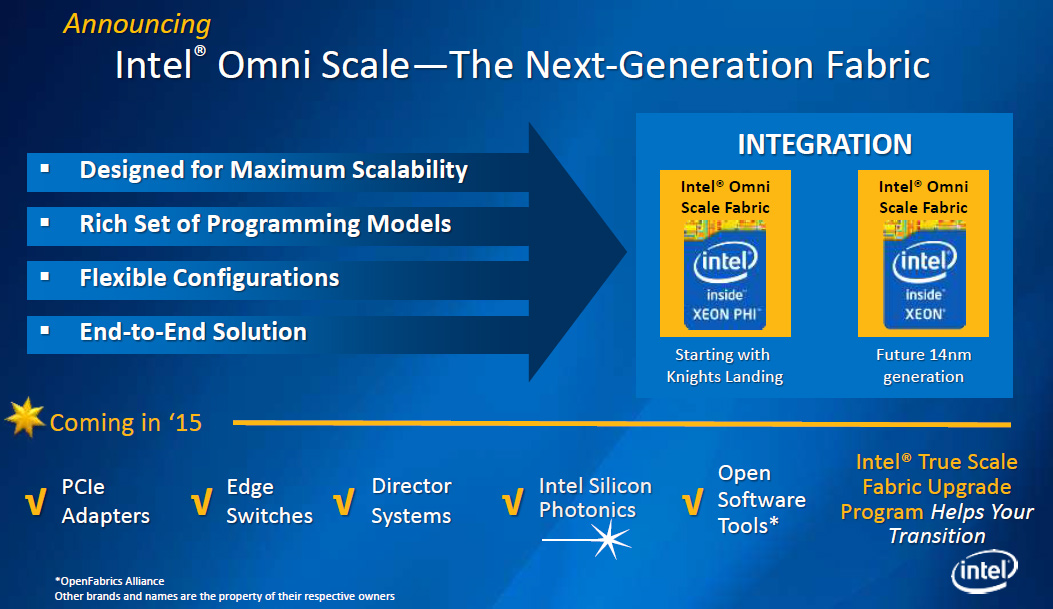
The new KNL co-processors will sport high-speed Omni Scale fabric that will be integrated on-package. This integration along with the fabric's HPC-optimized architecture is designed to address the performance, scalability, reliability, power and density requirements of future HPC deployments. The same fabric will be integrated into the next-generation Intel Xeon central processing units (CPUs) that will be made using 14nm fabrication process.
As reported, the Xeon Phi “Knights Landing” will come with up to 16GB of high-bandwidth on-package memory, which will boost performance of memory bandwidth-dependent applications. This on-package memory will transform KNL chips into independent compute building blocks with massive resources. It is likely that the new Xeon Phi will rely on Micron Technology’s hybrid memory cube (HMC) stacked DRAMs.
Intel Xeon Phi “Knights Landing” co-processors will be available in both PCI Express card and standalone processor form-factors. The latter will be compatible with Intel Xeon sockets.
“Intel is re-architecting the fundamental building block of HPC systems by integrating the Intel Omni Scale fabric into Knights Landing, marking a significant inflection and milestone for the HPC industry,” said Charles Wuischpard, vice president and general manager of workstations and HPC at Intel. “Knights Landing will be the first true many-core processor to address today's memory and I/O performance challenges. It will allow programmers to leverage existing code and standard programming models to achieve significant performance gains on a wide set of applications. Its platform design, programming model and balanced performance makes it the first viable step towards exascale.”
Intel Xeon Phi processor code-named “Knights Landing” is scheduled to power HPC systems in the second half of 2015.
Discuss on our Facebook page, HERE.
KitGuru Says: While Intel continues to be relatively tight-lipped about technical specifications of the Xeon Phi “Knights Landing,” it is obvious that the new chip truly changes the game when it comes to high-performance computing. Thanks to integrated high-performance fabric, high-bandwidth memory and modern x86 cores, the KNL solutions will offer a lot of advantages both from performance and programmability points of view.

What ? “up tp 16GB On-package RAM!”!. IS this eDram inside each cluster of 4 cores ?. This would be wickedly expensive and why would a chip like this use normal DDR4 ram anymore ?. Unless it uses a large pool of Ram Cache running off the north-bridge via a ring based bus to other chips sharing the cache pool. It seems with 14nm at their disposal, Intel has finally thrown in everything they have got in terms of design restrictions when they got the power budget down by a significant level. Contrast this with AMD using 28nm to optimise for max transistors and limiting frequencies in order to get the wanted performance level.