

The evolution of language models has accelerated considerably in the last few years. Users can now easily deploy sophisticated LLMs (Large Language Models) through applications like LM Studio. For users who work with such applications, a system capable of efficiently handling AI workloads is important, and AMD wants to ensure it can deliver such a system to users.
LM Studio is rooted in the llama.cpp project, a framework that enables LLMs' rapid and efficient deployment. Its lightweight design boasts zero dependencies and allows CPU-based acceleration, though it also supports GPU enhancements. By leveraging AVX2 instructions, LM Studio boosts the performance of modern LLMs running on x86-based CPUs. With AMD's Ryzen AI APUs, particularly with llama.cpp-dependent applications like LM Studio, users can leverage the capabilities of these processors to accelerate the development and deployment of AI applications.
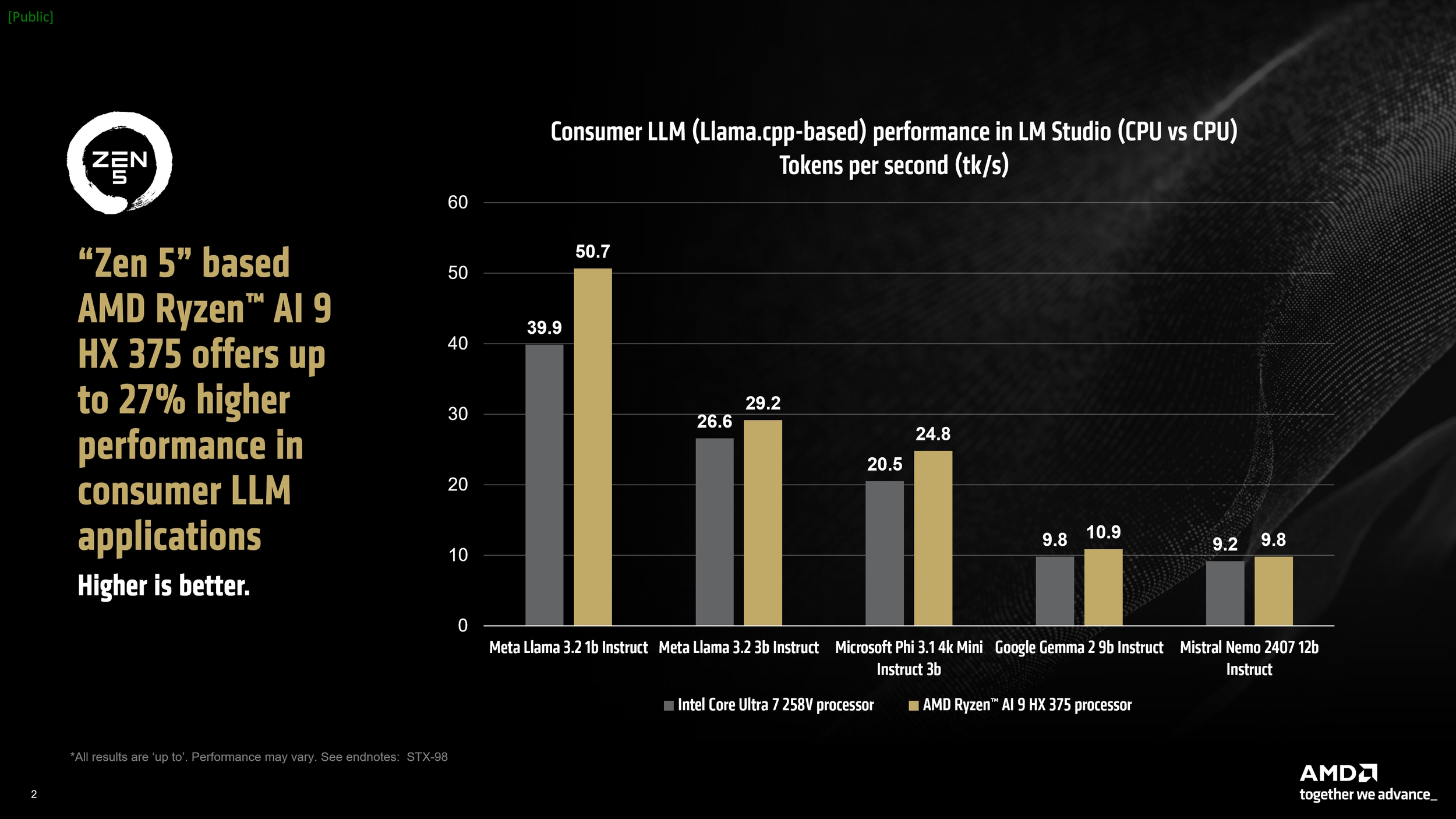
As AMD noted, LLM performance is sensitive to memory speeds. For example, in AMD's testing, an Intel laptop clocked at 8533 MT/s outpaced an AMD laptop running at 7500 MT/s. However, the AMD Ryzen AI 9 HX 375 still managed to achieve a 27% improvement in tokens per second (tk/s), a metric that indicates how quickly an LLM can generate textual output.
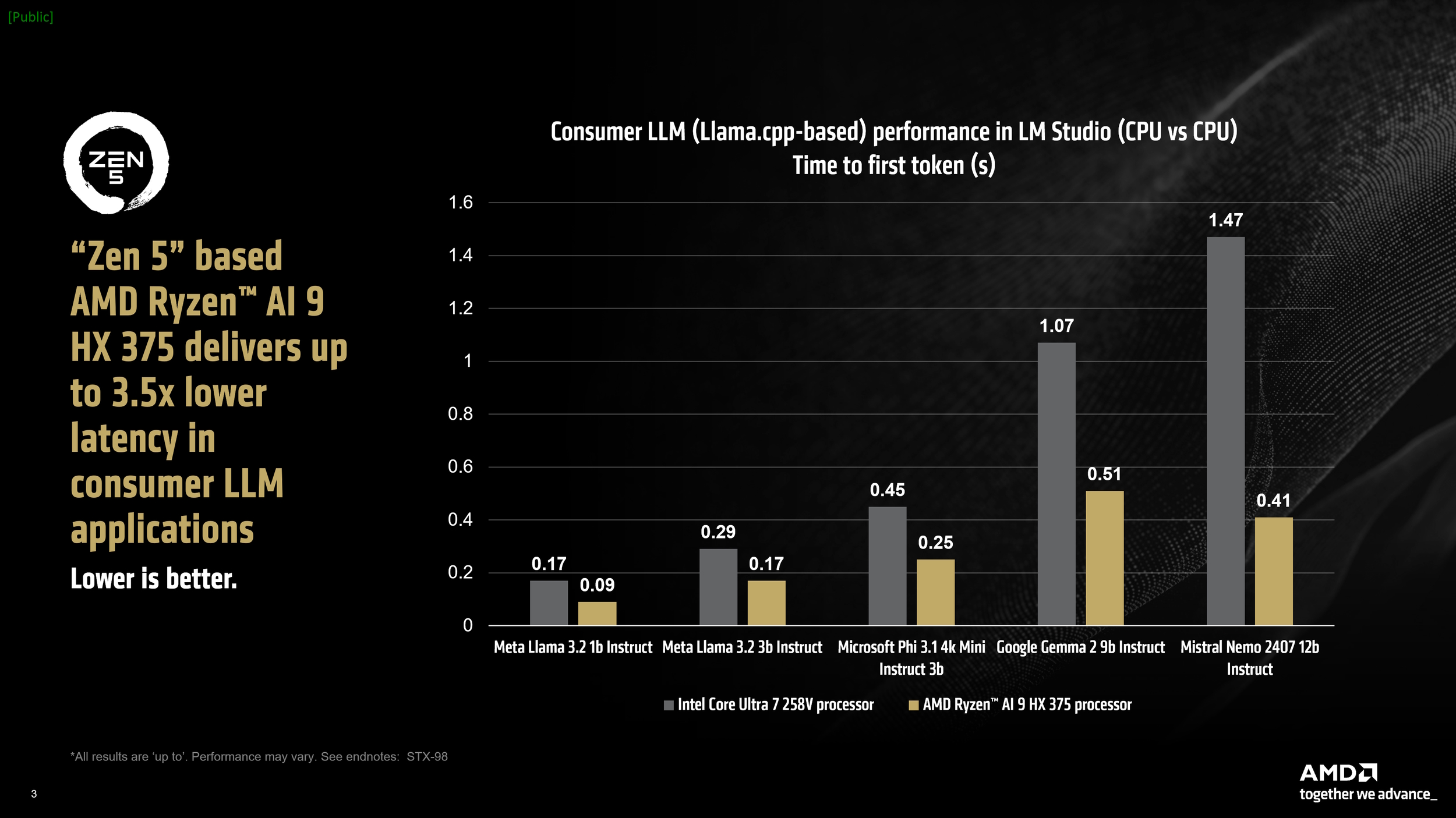
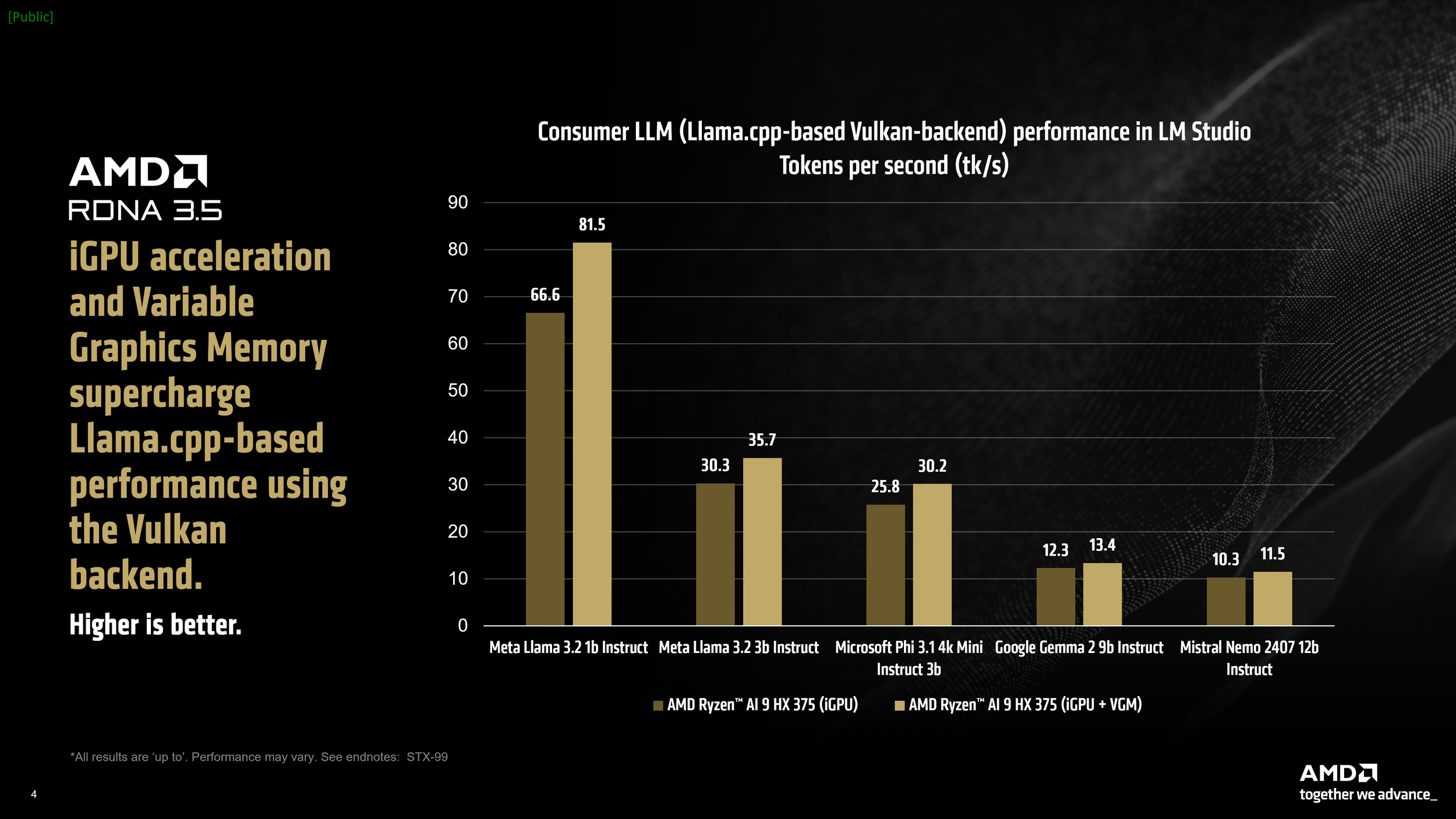
Under testing, the AMD Ryzen AI 9 HX 375 CPU processed up to 50.7 tokens per second using the Meta Llama 3.2 1b Instruct model at 4-bit quantisation. Another key performance indicator, “time to first token”, showed the same processor outperforming its rivals by up to 3.5x in larger model implementations. Moreover, LM Studio features a version of llama.cpp optimised for acceleration through Vulkan, which results in significant performance gains. By enabling GPU offloading in LM Studio, we observed a remarkable 31% improvement in Meta Llama 3.2 1b relative to its CPU-only mode. In more demanding models, the gains were a modest 5.1% increase.
Variable Graphics Memory (VGM), introduced with the Ryzen AI 300 series, is also helpful for AI workloads. It allows users to expand the traditional 512MB dedicated memory allocation for integrated GPUs. By increasing this allocation to up to 75% of available system RAM, VGM enhances performance in memory-intensive applications. AMD tests revealed a 22% performance increase in the Meta Llama 3.2 1b with only VGM enabled (16GB), increasing to 60% when using GPU acceleration and VGM together.
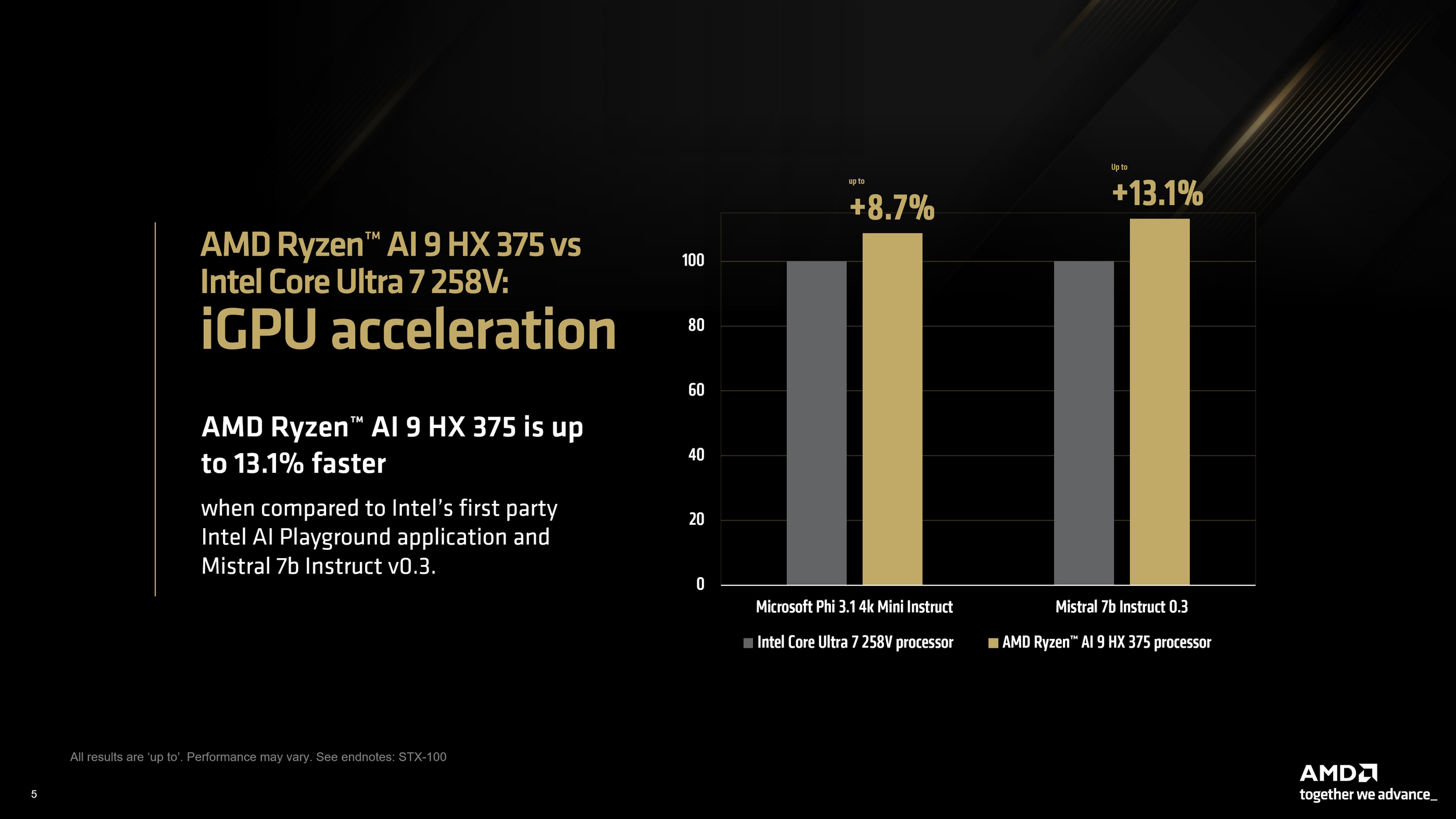
Larger models, like the Mistral Nemo 2407 12b, also benefitted, with performance improvements of up to 17% against CPU-only benchmarks. Lastly, using the Mistral 7b v0.3 and Microsoft Phi 3.1 Mini models from Intel AI Playground, AMD showed that the Ryzen AI 9 HX 375 outperforms the Core Ultra 7 258V by 8.7% and 13.1%, respectively.
KitGuru says: If you're looking for a laptop for LLM applications, you should at least consider something equipped with a Ryzen AI 300 series processor.
